Tiếp thị tự động hóa (Marketing automation) là một nền tảng phần mềm (software platform) giúp các công ty có được mối quan hệ và trải nghiệm khách hàng được cá nhân hóa cao trên quy mô lớn, bằng cách tự động hóa quy trình làm việc của các chiến dịch tiếp thị để tạo ra nhiều khách hàng tiềm năng hơn, chốt được nhiều giao dịch hơn và đo lường thành công tiếp thị thông qua các kênh truyền thông khác nhau:

Các công cụ tự động hóa tiếp thị được sử dụng để giải quyết toàn bộ vòng đời của khách hàng bằng cách đồng hành với khách hàng tiềm năng (prospect) và khách hàng (customer) để nâng cao hành trình và nâng cao ARPU (Doanh thu trung bình tương ứng với mỗi khách hàng) của họ ở mỗi giai đoạn. Các trường hợp sử dụng tự động hóa tiếp thị phổ biến nhất như sau:

Tự động hóa tiếp thị tận dụng tiềm năng cao của lượng dữ liệu (Big Data) mà các công ty sở hữu, bằng cách sử dụng máy học để chia nhỏ các tập dữ liệu theo nhu cầu cụ thể (segmentation) (tinh chỉnh mục tiêu chiến dịch), cho điểm (đánh giá thái độ của khách hàng) và phát hiện cơ hội (tiết lộ các liên kết và tương quan ẩn), cho phép đảm bảo chiến dịch tiếp thị hiệu quả, đạt hiệu quả hoạt động và tăng trưởng doanh thu nhanh hơn. Các mô hình học máy AI mô tả và dự đoán giúp xác định khách hàng và nhu cầu của họ, để tăng khả năng họ phản hồi với một chiến dịch nhất định thông qua các kênh truyền thông cụ thể:

Bước 1: Phân tách tập dữ liệu (Data Segmentation)
 Algorithm step-by-step")
Bước 2: Chấm điểm hồ sơ khách hàng (Customer Profile Scoring)
- Rules engine (hệ thống chấm điểm theo quy tắc): bằng cách tăng và giảm điểm số hàng đầu dựa trên tổng trọng số của tương tác, ví dụ: [+1 điểm] cho lượt truy cập trang web, [+5 điểm] nhấp vào Email liên hệ, [+10 điểm] nhấp vào danh mục sản phẩm, [+20 điểm] tải xuống hướng dẫn người mua, [+30 điểm] truy cập hình thức thanh toán, [-10 điểm] sau 1 tháng không hoạt động, [-30 điểm] hủy đăng ký nhận bản tin. Hạn chế: trọng số của tương tác được xác định theo cách thủ công và cần điều chỉnh liên tục
- Predictive analytics (Phân tích dự đoán) đặc biệt là regression (hồi quy), chẳng hạn như hồi quy logistic có thể được coi là xác suất chuyển đổi, nó cho phép:
- Loại bỏ việc chọn các yếu tố dự đoán theo cách thủ công, bằng cách sử dụng các thuật toán lựa chọn tính năng như lùi lại từng bước để chọn thông tin phù hợp nhất về các khách hàng tiềm năng từ thông tin nhân khẩu học, hành vi trực tuyến và tương tác qua email / xã hội.
- Loại bỏ việc xác định trọng số (weight) vì nó được thuật toán hồi quy tự động xác định trong quá trình đào tạo mô hình.
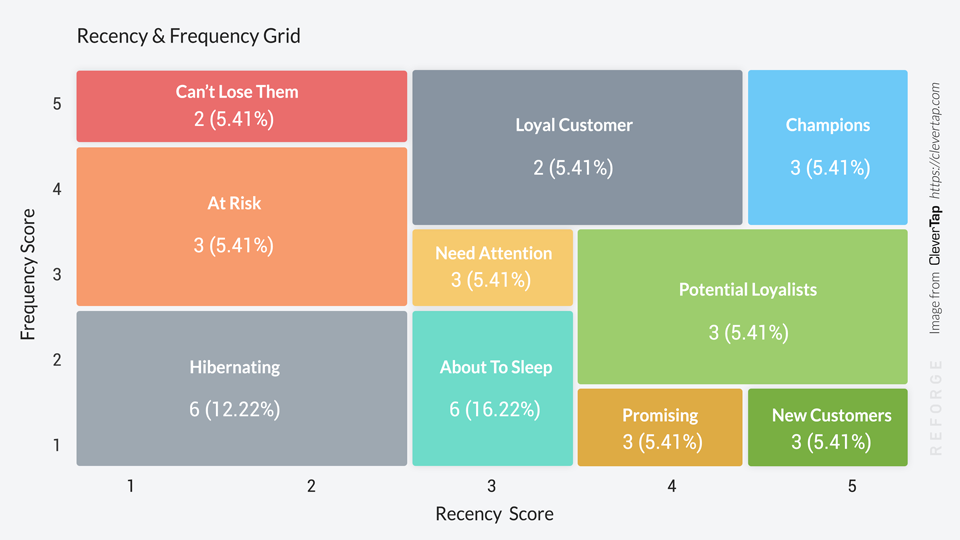
- Recency score(điểm số lần truy cập gần đây): Xác định khoảng thời gian [mua ngày gần đây nhất, mua ngày xa nhất] và xếp nó thành 3, 4 hoặc 5 xếp hạng. Những khách hàng đã mua gần đây có nhiều khả năng mua lại hơn là những khách hàng đã mua thêm trong quá khứ.
- Frequency score(điểm tần suất): Xác định khoảng thời gian [tần suất mua hàng cao nhất, tần suất mua hàng thấp nhất] và xếp nó thành 3, 4 hoặc 5 xếp hạng. Những khách hàng đã mua nhiều hàng hơn trong quá khứ có nhiều khả năng phản hồi hơn là những khách hàng đã mua ít hơn.
- Monetary score (điểm số tiền tệ): Xác định [giá trị tiền tệ cao nhất, giá trị tiền tệ thấp nhất] và xếp nó vào 3, 4 hoặc 5 xếp hạng Những khách hàng đã chi tiêu nhiều hơn (tổng cộng cho tất cả các giao dịch mua) trong quá khứ có nhiều khả năng phản hồi hơn những người đã chi tiêu ít hơn.