
Paper links:
As more and more data is collected every day, we are moving from the age of information to the age of recommendation. One of the key reasons why we need recommendations in modern society, is that now people have too much options to choose from. This is possible due to the prevalence of the internet. In the past, people use to shop in a physical store, the availability of options were limited and depended on the size of the store, availability of product and marketing techniques. For instance, the number of movies that can be placed in a store depends on the size of that store. By contrast, nowadays, the internet allows people to access abundant resources online. Netflix, for example, has a huge collection of movies. . Although the amount of available information increased, a new problem arose as people had a hard time selecting the items they actually want to see. This is where the recommender system comes in.
A recommender system refers to a system that is capable of predicting the future preference of a set of items for a user. It is a subclass of information filtering system that seeks to predict the rating or preference a user would give to a particular item. These systems are utilized enormously across multiple industries. Recommender systems are most commonly used as playlist generators for video and music services like Netflix, YouTube and Spotify, or product recommenders for services such as Amazon, or content recommenders for social media platforms such as Facebook and Twitter. A huge amount of research and wealth is invested by industries to find out techniques to get great recommendation and improve user experience.


This article will give you a basic understanding of a typical way for building a recommender system, Collaborative Filtering. We will understand and implement Collaborative Filtering together using Apache Spark with Scala programming Language. Since this is going to be a deep dive into Apache Spark’s and Scala internals, I would expect you to have some understanding about both. Although I’ve tried to keep the entry level for this article pretty low, you might not be able to understand everything if you’re not familiar with the general workings of it. Proceed further with that in mind.
Collaborative Filtering


Multiple researcher in different industries use multiple approaches to design their recommendation system. Traditionally, there are two methods to construct a recommender system:
1) Content-based recommendation
2) Collaborative Filtering
First one analyses the nature of each item and aims to find the insights of the data to identify the user preferences. Collaborative Filtering, one the other hand, does not require any information about the items or the user themselves. It recommends the item based on user past experience and behavior. The key idea behind Collaborative Filtering is that similar users share similar interest, people with similar interest tends to like similar items. Hence those items are recommended to similar set of users. For example, if a person A has same opinion as a person B on an issue. Then A is more likely to have B’s opinion on different issue.
Talking in a Mathematical term, assume there are x users and y items, we use a matrix with size x*y to denote the past behavior of users. Each cell in the matrix represents the associated opinion that a user holds. For instance, Matrix[i, j] denotes how user ‘i’ likes item ‘j’. Such matrix is called utility matrix. Collaborative Filtering is like filling the blank (cell) in the utility matrix that a user has not seen/rated before based on the similarity between users or items.
As mentioned above, Collaborative Filtering (CF) is a mean of recommendation based on user’s past behavior. There are two categories of CF:
· User-based: measure the similarity between target users and other users
· Item-based: measure the similarity between the items that target users rates/ interacts with and other items
Use Case


For the sake of our use-case, I will explain Item-based Collaborative Filtering but the working is almost same for user-based Collaborative Filtering. We know that we need to find the similarity between the items in order to recommend it to similar users. In this use case, we aim to recommend movies to our customers. In order to do that we will target movie ratings as a domain to find similarity between two movies. You can download the required movie ratings dataset. This dataset contains two csv’s movies.csv and ratings.csv which looks like below.




We proceed with the assumption that if a user A has watch movie ‘i’ and rated it as good, then he/she with also like movies with similar ratings overall. But how do we measure similarity? Cosine similarity is a measure of similarity between two non-zero vectors of an inner product space that measures the cosine of the angle between them.

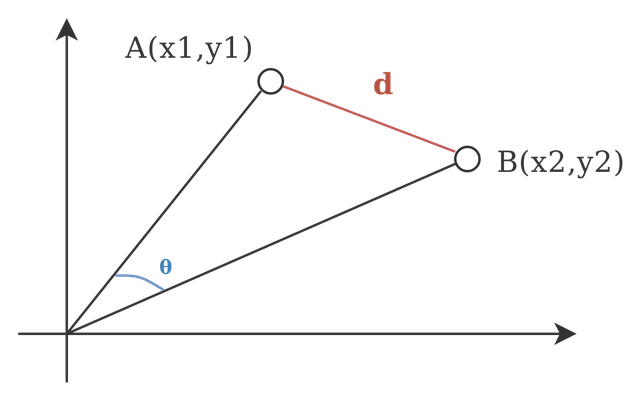
As mentioned earlier we will construct a User Ratings vs Movies utility matrix. Say for example, we have x users and y movies. Each cell represent the associated opinion that a user holds about that particular movie. For example M[i,j] represent the opinion of ‘i’th user for ‘j’th movie.
Hence for this use case, we gather ratings of multiple users for movies A and B and follow following steps:
1) Consider two movies A and B out of the utility graph.
2) For each movie form two vector of the rating score for multiple user.
3) From above two vectors, calculate cosine similarity score.
4) If score is above the pre-determined threshold score than those two movies are similar.
5) Now, we can recommend a user who have watch movie A, that he/she can also watch movie B.
Apache Spark
Apache Spark is a highly developed engine for data processing on large scale over thousands of compute engines in parallel. This allows maximizing processor capability over these compute engines. Spark has the capability to handle multiple data processing tasks. Hence we use spark parallel processing in order to achieve our use case.
Scala
Scala helps to dig deep into the Spark’s source code that aids developers to easily access and implement new features of Spark. Developers can get object oriented concepts very easily. By using Scala language, a perfect balance is maintained between productivity and performance. Spark is built on the top of Scala programming language, hence it offers maximum speed with it.
Code Working
In order to get maximum understanding of collaborative filtering, I haven’t used any pre-defined library to implement our use case. Code in scala is pretty straight forward and completely based on the steps we discussed above. There are few transformation and structuring of data involved before we calculate similarity between movies. All the functions defined and steps involved in the code is explained as follows:
- Construct utility matrix by Mapping input RDD with userId, ratings and movieId in following tuple `(userId, (movieID, rating))`.


2) Find every movie pair rated by same user, we are achieving this by using a “self-join” operation. At this point we have data in following format
`(userId, [(movieId, rating), (movieId, Rating), …])`.


3) Filter out duplicate pairs with same movieId’s.


4) Out of the array of movie and ratings constructed in step 2, construct new map tuple with key as movie pair and value as respective ratings like as follows
`((movieId1, movieId2), (rating1, rating2))`


5) Apply groupByKey() to get every rating pair found for each movie pair over the map that we have created in step 4.


6) From step 5 construct rating vector for each movie in pair and calculate the cosine similarity score from that vector


7) Sort, save or cache the similarity result for each movie pair


8) Set a similarity threshold and user engagement number to improve relevance of results.

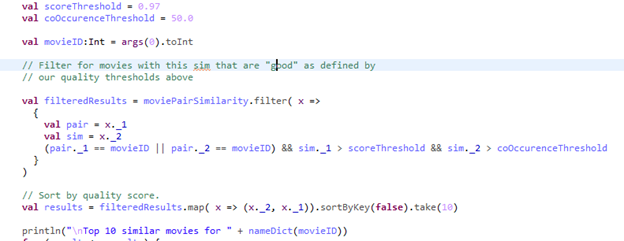
9) Get input parameter and display results with movies names as recommendation
You can find full working code here.
Results


Conclusion
We have discussed and implemented Collaborative Filtering using Apache Spark with Scala. This techniques have its own pro’s and con’s. As user behavior changes with time the accuracy of this techniques varies time to time. We can also enhance its accuracy and overcome limitations by some pre-processing based on genres, style and content. I feel Apache Spark is a great tool to implement features like this and can serve in more advance and real time recommendations. If you have reached till here, Congrats! you have implemented your own recommendation engine. I will keep on posting more content on big data and data science. Till then stay tuned and Happy Learning!

