Các công ty / tập đoàn kinh doanh trong lĩnh vực bán lẻ sẽ phải "thích nghi" như thế nào trong một nền kinh tế suy thoái #Recession ?
Mô hình Smart Retail O2O được đề xuất như framework để mọi người tham khảo. Trọng tâm của mô hình là tổ chức quản lý dữ liệu khách hàng ngành Retail có tính hệ thống hơn #RightData, sử dụng công nghệ thông minh #RightTech với quy trình tối ưu cho từng nhóm segment khách hàng #RightProcess
The adoption of retail analytics solutions is increasing rapidly as more retailers worldwide are realizing significant returns from using BI and analytics platforms.
Retail analytics trends of 2020 will help the retail business to adopt an agile and cohesive data management approach and devise new marketing strategies to drive better business outcomes. Retail data analytics is going to change the retail business scenario dramatically in 2020. Here are the top four retail analytics trends to watch out for in 2020:
Omnichannel experience: When it comes to offering splendid customer experience, retail businesses need to bridge the gap between in-store and online shopping platforms. Retail data analytics solutions are helping cashiers and customers to check the availability of stock and make selections online. Currently, the customer-centric models are helping retail businesses to integrate online and offline platforms to provide an omnichannel experience to customers.
Personalization: Personalization is the major retail analytics trend of 2020. Retail businesses are focusing on retaining customers through various activities like interacting models and recommending items. Such activities help companies to improve their marketing strategies and cut down on marketing spend while providing personalized services to customers.
Predictive Analytics: Currently every retailer is leveraging predictive analytics to interpret and analyze historical data and make predictions. Hence it is the hottest trend of retail data analytics. Predictive analytics enables companies to fetch data related weather patterns and local events that affect the business.
Dynamic pricing models: Dynamic pricing is one of the most important retail analytics trends of 2020. Price elasticity helps in determining product prices based on current market demands. This can further help in increasing demand and enhancing customer satisfaction rates.
Ever since I read this powerful statement by a German-born theoretical physicist, our super intelligent Mr. Albert Einstein, it has changed my perspective of looking at learning and development process. In such simple words, he has given me wisdom to think about making my each training an experience than a boring classroom session; an experience which people remember for lifetime, a happy learning experience which is a transition from being someone to being someone better, an experience which has made a difference.
Let me break down the learning process with a relevant example to decipher this statement and understand it well.
Learning starts with awareness
An awareness that I need to learn this in order to move forward or change something in my life is the first step towards learning. Learning without the awareness of its requirement doesn’t really help. For an example, an awareness that I need become a healthy person is the first step towards learning how to become a healthy person.
It needs a lot of assumptions and information
Second step towards learning is assuming a lot of things and gathering information basis on those assumption. For an example, the assumption for becoming a healthy person is that I need to look lean and to look lean I need to lose weight. And then all the information is being gathered from reliable sources about how to lose weight. As per your information, you start dieting by starving and depriving from food you like and eating the food which are considered to be healthy.
Expert’s advice
An expert’s advice is the third step towards your learning curve where an expert validates whether your assumptions and information are right or wrong. An expert also gives you the right direction to move if you are heading towards something wrong. For above example, an expert here will tell you that being lean is not being healthy, but health is a state of complete physical well-being by eating right amount of food at right time with exercising and balancing all the required nutrients. So your assumption here towards a good health is redirected.
Planning how to learn
Now when an expert has directed the learning towards right direction, the fourth step towards learning comes when you ask yourself questions like ‘What does it require out of me?’, ‘what is my role going to be and how do I achieve it?’. For example, now you will plan a schedule for your food intakes and exercises like whether to go to a gym or hire a personal trainer or go and learn yoga or just do normal walk every day.
Experiencing and learning
Now when we know the right information and we are sure that we are going in right direction to achieve our objective, the learning process starts with an actual experience of it. For an example, you might realise that your hunger still remains the same, your food intake still remains the same, your taste buds are still being satisfied and you are not compromising on anything you feel like eating but all you are doing is eating smaller portions, at slower pace and at regular intervals in a day and within 6 months you lose fat from your body and experience your first transition of learning curve for becoming healthy.
Now that’s how learning anything is an experience and rest all is just information.
At BigDataVietnam.org, we understand this process thoroughly and make sure that all the learning services we provide go through all these steps right from getting aware about what needs to be learnt to learning it through an experience in right direction suggested by our experts of the field.
As more and more data is collected every day, we are moving from the age of information to the age of recommendation. One of the key reasons why we need recommendations in modern society, is that now people have too much options to choose from. This is possible due to the prevalence of the internet. In the past, people use to shop in a physical store, the availability of options were limited and depended on the size of the store, availability of product and marketing techniques. For instance, the number of movies that can be placed in a store depends on the size of that store. By contrast, nowadays, the internet allows people to access abundant resources online. Netflix, for example, has a huge collection of movies. . Although the amount of available information increased, a new problem arose as people had a hard time selecting the items they actually want to see. This is where the recommender system comes in.
A recommender system refers to a system that is capable of predicting the future preference of a set of items for a user. It is a subclass of information filtering system that seeks to predict the rating or preference a user would give to a particular item. These systems are utilized enormously across multiple industries. Recommender systems are most commonly used as playlist generators for video and music services like Netflix, YouTube and Spotify, or product recommenders for services such as Amazon, or content recommenders for social media platforms such as Facebook and Twitter. A huge amount of research and wealth is invested by industries to find out techniques to get great recommendation and improve user experience.
This article will give you a basic understanding of a typical way for building a recommender system, Collaborative Filtering. We will understand and implement Collaborative Filtering together using Apache Spark with Scala programming Language. Since this is going to be a deep dive into Apache Spark’s and Scala internals, I would expect you to have some understanding about both. Although I’ve tried to keep the entry level for this article pretty low, you might not be able to understand everything if you’re not familiar with the general workings of it. Proceed further with that in mind.
Collaborative Filtering
Multiple researcher in different industries use multiple approaches to design their recommendation system. Traditionally, there are two methods to construct a recommender system:
1) Content-based recommendation
2) Collaborative Filtering
First one analyses the nature of each item and aims to find the insights of the data to identify the user preferences. Collaborative Filtering, one the other hand, does not require any information about the items or the user themselves. It recommends the item based on user past experience and behavior. The key idea behind Collaborative Filtering is that similar users share similar interest, people with similar interest tends to like similar items. Hence those items are recommended to similar set of users. For example, if a person A has same opinion as a person B on an issue. Then A is more likely to have B’s opinion on different issue.
Talking in a Mathematical term, assume there are x users and y items, we use a matrix with size x*y to denote the past behavior of users. Each cell in the matrix represents the associated opinion that a user holds. For instance, Matrix[i, j] denotes how user ‘i’ likes item ‘j’. Such matrix is called utility matrix. Collaborative Filtering is like filling the blank (cell) in the utility matrix that a user has not seen/rated before based on the similarity between users or items.
As mentioned above, Collaborative Filtering (CF) is a mean of recommendation based on user’s past behavior. There are two categories of CF:
· User-based: measure the similarity between target users and other users
· Item-based: measure the similarity between the items that target users rates/ interacts with and other items
Use Case
For the sake of our use-case, I will explain Item-based Collaborative Filtering but the working is almost same for user-based Collaborative Filtering. We know that we need to find the similarity between the items in order to recommend it to similar users. In this use case, we aim to recommend movies to our customers. In order to do that we will target movie ratings as a domain to find similarity between two movies. You can download the required movie ratings dataset. This dataset contains two csv’s movies.csv and ratings.csv which looks like below.
movies.csv
ratings.csv
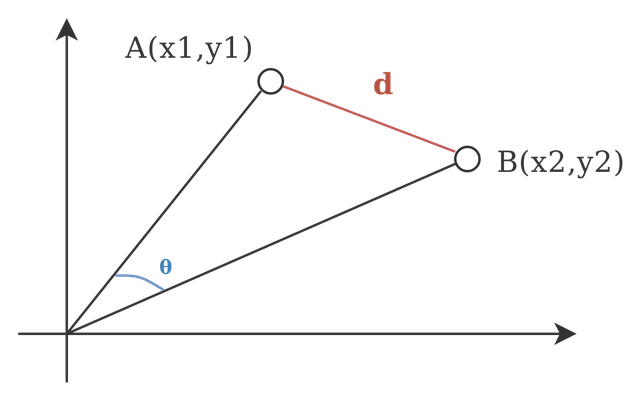
We proceed with the assumption that if a user A has watch movie ‘i’ and rated it as good, then he/she with also like movies with similar ratings overall. But how do we measure similarity? Cosine similarity is a measure of similarity between two non-zero vectors of an inner product space that measures the cosine of the angle between them.
As mentioned earlier we will construct a User Ratings vs Movies utility matrix. Say for example, we have x users and y movies. Each cell represent the associated opinion that a user holds about that particular movie. For example M[i,j] represent the opinion of ‘i’th user for ‘j’th movie.
Hence for this use case, we gather ratings of multiple users for movies A and B and follow following steps:
1) Consider two movies A and B out of the utility graph.
2) For each movie form two vector of the rating score for multiple user.
3) From above two vectors, calculate cosine similarity score.
4) If score is above the pre-determined threshold score than those two movies are similar.
5) Now, we can recommend a user who have watch movie A, that he/she can also watch movie B.
Apache Spark
Apache Spark is a highly developed engine for data processing on large scale over thousands of compute engines in parallel. This allows maximizing processor capability over these compute engines. Spark has the capability to handle multiple data processing tasks. Hence we use spark parallel processing in order to achieve our use case.
Scala
Scala helps to dig deep into the Spark’s source code that aids developers to easily access and implement new features of Spark. Developers can get object oriented concepts very easily. By using Scala language, a perfect balance is maintained between productivity and performance. Spark is built on the top of Scala programming language, hence it offers maximum speed with it.
Code Working
In order to get maximum understanding of collaborative filtering, I haven’t used any pre-defined library to implement our use case. Code in scala is pretty straight forward and completely based on the steps we discussed above. There are few transformation and structuring of data involved before we calculate similarity between movies. All the functions defined and steps involved in the code is explained as follows:
Construct utility matrix by Mapping input RDD with userId, ratings and movieId in following tuple `(userId, (movieID, rating))`.
2) Find every movie pair rated by same user, we are achieving this by using a “self-join” operation. At this point we have data in following format
3) Filter out duplicate pairs with same movieId’s.
4) Out of the array of movie and ratings constructed in step 2, construct new map tuple with key as movie pair and value as respective ratings like as follows
`((movieId1, movieId2), (rating1, rating2))`
5) Apply groupByKey() to get every rating pair found for each movie pair over the map that we have created in step 4.
6) From step 5 construct rating vector for each movie in pair and calculate the cosine similarity score from that vector
7) Sort, save or cache the similarity result for each movie pair
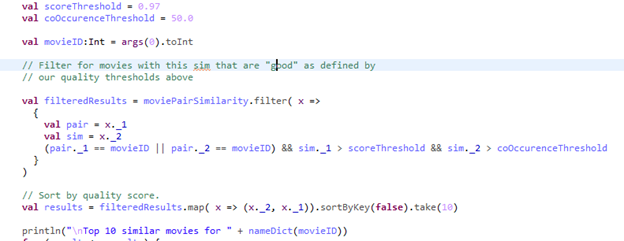
8) Set a similarity threshold and user engagement number to improve relevance of results.
9) Get input parameter and display results with movies names as recommendation
We have discussed and implemented Collaborative Filtering using Apache Spark with Scala. This techniques have its own pro’s and con’s. As user behavior changes with time the accuracy of this techniques varies time to time. We can also enhance its accuracy and overcome limitations by some pre-processing based on genres, style and content. I feel Apache Spark is a great tool to implement features like this and can serve in more advance and real time recommendations. If you have reached till here, Congrats! you have implemented your own recommendation engine. I will keep on posting more content on big data and data science. Till then stay tuned and Happy Learning!