Phân tích (Analytics) và học máy (Machine Learning)
Ví dụ: Làm sao dự đoán giả thiết "nếu ta giảm giá thêm 5% thì sẽ tăng doanh số bán hàng lên 10% ?" bằng dữ liệu bạn có từ 6 tháng qua ?
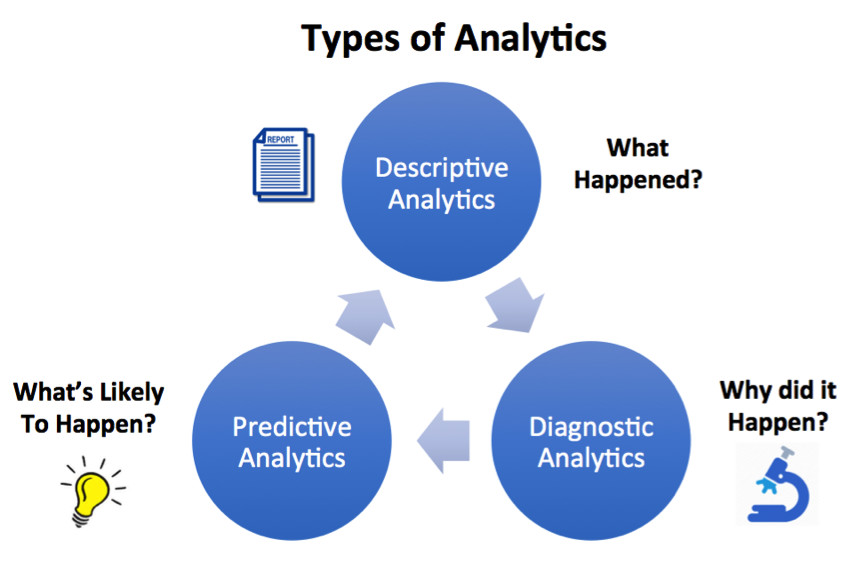
Analytics có 3 kỹ thuật chính, bao gồm:
Analytics mô tả (Descriptive Analytics): Để xác định điều gì đã xảy ra? Điều này thường liên quan đến các báo cáo giúp mô tả những gì đã xảy ra. Ví dụ: để so sánh doanh thu của tháng này với cùng thời điểm năm ngoái.
Phân tích chẩn đoán (Diagnostic Analytics): Cố gắng giải thích lý do tại sao điều này xảy ra, thường liên quan đến việc sử dụng trang tổng quan với khả năng OLAP để tìm hiểu và điều tra dữ liệu cùng với các kỹ thuật Khai phá dữ liệu để tìm mối tương quan.
Phân tích dự đoán (Predictive Analytics): Cố gắng ước tính điều gì có thể xảy ra. Có thể phân tích dự báo được sử dụng để chọn bạn làm người đọc tiềm năng của bài viết này dựa trên tiêu đề, sở thích và liên kết công việc của bạn cho người khác.
Học máy (ML) phù hợp với không gian Predictive Analytics.
Học máy là một tập hợp con của Trí tuệ nhân tạo AI, nhờ đó máy học được từ kinh nghiệm quá khứ, tức là. Dữ liệu. Không giống như lập trình truyền thống, nơi mà nhà phát triển cần dự đoán và mã hóa mọi điều kiện tiềm năng, giải pháp Machine Learning có hiệu quả điều chỉnh đầu ra dựa trên dữ liệu.
Thuật toán Học máy không có nghĩa là viết mã, nhưng nó xây dựng một mô hình máy tính (ML model) về hành vi của dữ liệu, sau đó nó sửa đổi dựa trên cách nó được đào tạo.
Làm thế nào nó hoạt động?
Phần mềm lọc spam là một ví dụ tuyệt vời. Nó sử dụng kỹ thuật Machine Learning để tìm hiểu cách nhận dạng spam từ hàng triệu thư. Nó hoạt động bằng cách sử dụng các kỹ thuật thống kê để giúp xác định các mẫu.
Ví dụ: nếu cứ 85 trong tổng số 100 email, bao gồm các từ “rẻ” và “Viagra” được tìm thấy là thư spam, chúng ta có thể nói với sự tự tin 85% rằng chúng thực sự là spam. Kết hợp điều này với một số chỉ báo khác (ví dụ: từ người gửi bạn chưa bao giờ nhận được thư) và thử nghiệm thuật toán chống lại một tỷ email khác, chúng ta có thể cải thiện độ tin cậy và chính xác theo thời gian.
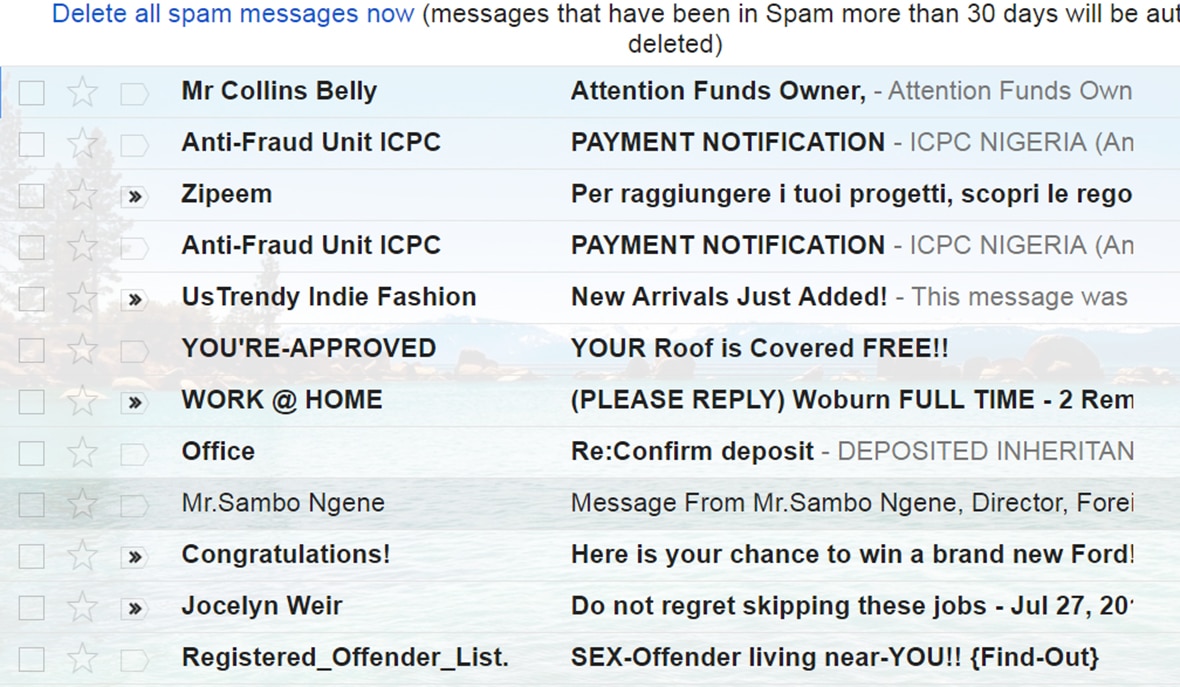
Trong thực tế, Google cho biết nó bây giờ dừng lại khoảng 99,99% thư rác được gửi đi.
Ví dụ về máy học
Hiện có hàng trăm ứng dụng đã sẵn sàng bao gồm: -Tiếp thị được nhắm mục tiêu (Targeted Marketing): Được Google và Facebook sử dụng để nhắm mục tiêu quảng cáo dựa trên sở thích cá nhân và bởi Netflix đề xuất phim để xem và Amazon đề xuất các sản phẩm để mua.
Ghi điểm tín dụng (Credit Scoring): Ngân hàng sử dụng dữ liệu thu nhập (ước tính từ nơi bạn sống), tuổi và tình trạng hôn nhân của bạn để dự đoán liệu bạn có mặc định cho khoản vay không.
Phát hiện gian lận thẻ (Card Fraud Detection): Được sử dụng để ngăn chặn sử dụng gian lận thẻ tín dụng hoặc thẻ ghi nợ trực tuyến dựa trên thói quen chi tiêu trước đó và có khả năng của bạn.
Phân tích giỏ hàng (Basket Analysis): Được sử dụng để dự đoán ưu đãi đặc biệt nào bạn có nhiều khả năng sử dụng dựa trên thói quen mua hàng triệu khách hàng tương tự.
Trong một trường hợp gây tranh cãi, nhà bán lẻ Hoa Kỳ Target đã sử dụng phân tích giỏ 25 sản phẩm mỹ phẩm và sức khỏe khác nhau để dự đoán thành công hành vi mua hàng của phụ nữ đang mang thai kể cả ngày đến hạn có độ chính xác cao. Điều này phản tác dụng khi cha của một cô gái trẻ phàn nàn rằng Target đã khuyến khích các bà mẹ tuổi teen sau khi cô bị spam emails với những lời đề nghị đặc biệt liên quan đến việc mang thai.

Tóm lại, bạn cần (theo thứ tự ưu tiên):
- Mục tiêu (A Goal). Vấn đề bạn đang cố giải quyết. Ví dụ, thẻ tín dụng này có bị đánh cắp không? Giá cổ phiếu có tăng hay giảm? Phim nào khách hàng sẽ thích nhất?
- Rất nhiều dữ liệu (Lots of Data). Ví dụ: để dự đoán chính xác giá trị gia đình, bạn sẽ cần giá lịch sử chi tiết cùng với chi tiết thuộc tính mở rộng.
- Một chuyên gia (An Expert). Bạn sẽ cần một chuyên gia chuyên ngành hiểu được câu trả lời đúng để xác minh kết quả được tạo và xác nhận khi mô hình đủ chính xác.
- Một mô hình (A Pattern). Bạn đang tìm kiếm một mẫu trong dữ liệu. Nếu không có mẫu, bạn có thể có dữ liệu sai hoặc không đầy đủ hoặc có thể không có mẫu nào cả.
Các loại máy học
Phân tích dự đoán (Predictive analytics) cố gắng dự đoán kết quả trong tương lai dựa trên dữ liệu lịch sử và phương pháp phổ biến nhất được gọi là Học tập được giám sát (Supervised Learning).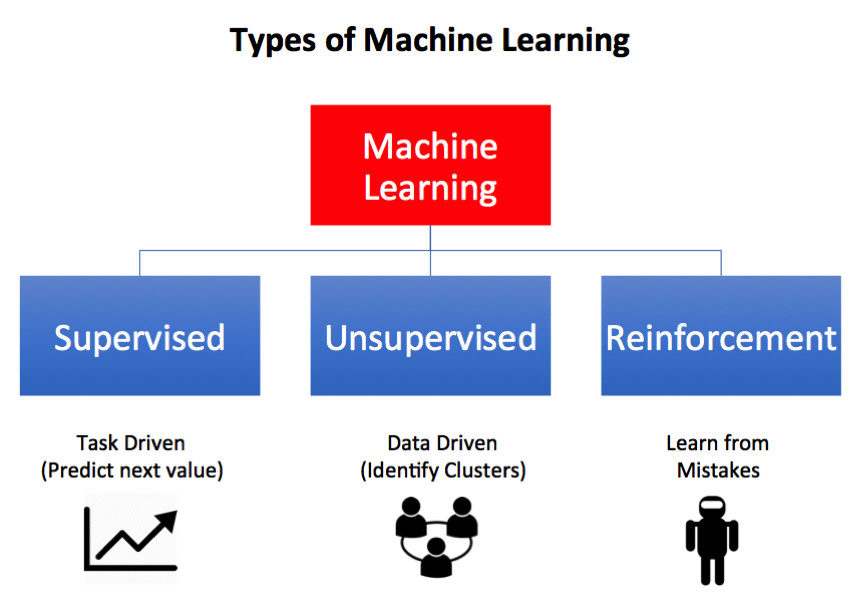
Các loại máy học là:
- Học tập được giám sát (Supervised Learning): Được sử dụng khi chúng ta biết câu trả lời chính xác từ dữ liệu trong quá khứ, nhưng cần phải dự đoán kết quả trong tương lai. Ví dụ: sử dụng giá nhà cũ để dự đoán giá trị hiện tại và tương lai. (ví dụ: Zillow dựa trên Hoa Kỳ hoặc Vương quốc Anh dựa trên Zoopla). Sử dụng hiệu quả quá trình cải tiến thống kê dựa trên thử nghiệm và lỗi, máy dần dần cải thiện độ chính xác bằng cách kiểm tra kết quả dựa vào một tập hợp các giá trị do người giám sát cung cấp.
- Học tập không được giám sát (Unsupervised Learning): Nơi không có câu trả lời đúng khác biệt, nhưng chúng ta muốn khám phá điều gì đó mới mẻ từ dữ liệu. Thường được sử dụng để phân loại hoặc nhóm dữ liệu, ví dụ: để phân loại nhạc trên Spotify, để giúp đề xuất những album bạn có thể nghe. Sau đó nó sẽ phân loại người nghe, để xem liệu họ có nhiều khả năng nghe Radiohead hay Justin Bieber hơn không. (Radiohead mỗi lần!).
- Học tập tăng cường (Reinforcement Learning): Không cần chuyên gia miền nhưng liên quan đến các cải tiến liên tục đối với mục tiêu được xác định trước. Đó là một kỹ thuật thường triển khai mạng Neural, ví dụ, DeepMind, trong đó AphaGo đã chơi một triệu trò chơi của Go chống lại chính nó để cuối cùng trở thành nhà vô địch thế giới.
Quá trình học máy
Không giống như hình ảnh tương lai của các máy học chơi cờ, hầu hết Machine Learning (hiện tại) khá mất thời gian và được minh họa trong sơ đồ dưới đây: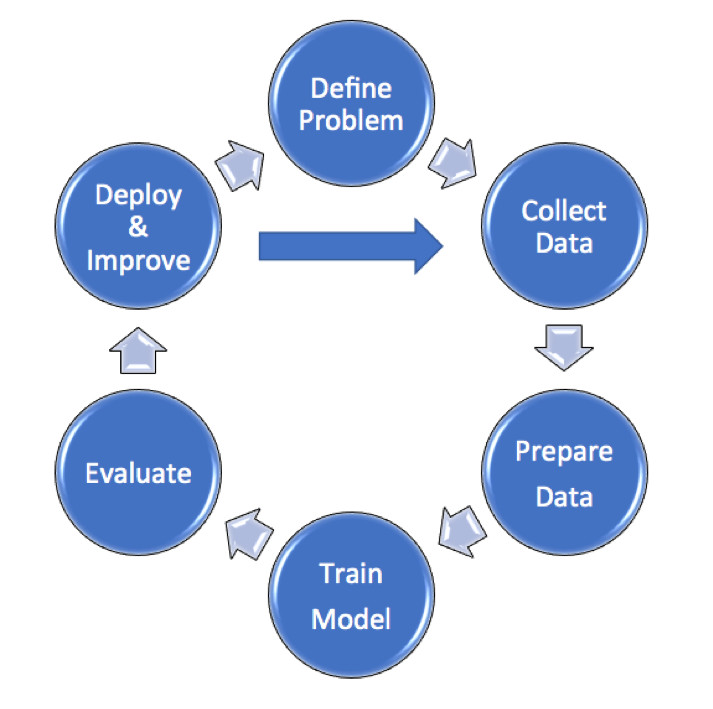
Xác định vấn đề (Define Problem): Như được chỉ ra trong bài viết khác của tôi, luôn luôn bắt đầu với một vấn đề được xác định rõ ràng và mục tiêu trong tâm trí.
Thu thập dữ liệu (Collect data): Khối lượng và số lượng dữ liệu thích hợp càng lớn, mô hình học máy sẽ càng chính xác hơn. Điều này có thể đến từ bảng tính, tệp văn bản và cơ sở dữ liệu ngoài các nguồn dữ liệu có sẵn trên thị trường.
Chuẩn bị dữ liệu (Prepare data): Bao gồm phân tích, làm sạch và hiểu dữ liệu. Loại bỏ hoặc sửa chữa các ngoại lệ (giá trị cực kỳ sai); điều này thường mất tới 60% tổng thời gian và công sức. Dữ liệu sau đó được chia thành hai phần riêng biệt, dữ liệu Đào tạo và Kiểm tra.
Đào tạo mô hình (Train Model): Chống lại một tập hợp dữ liệu đào tạo - được sử dụng để xác định các mẫu hoặc tương quan trong dữ liệu hoặc đưa ra dự đoán, đồng thời nâng cao độ chính xác bằng cách sử dụng phương pháp thử nghiệm lặp lại và sửa lỗi.
Đánh giá mô hình(Evaluate model): Bằng cách so sánh độ chính xác của kết quả với tập hợp dữ liệu thử nghiệm. Điều quan trọng là không đánh giá mô hình dựa trên dữ liệu được sử dụng để đào tạo hệ thống để đảm bảo kiểm tra không thiên vị và độc lập.
Triển khai và cải tiến (Deply & Improve): Việc này có thể liên quan đến việc thử một thuật toán hoàn toàn khác hoặc thu thập nhiều hoặc khối lượng dữ liệu lớn hơn. Ví dụ: bạn có thể cải thiện dự đoán giá nhà bằng cách ước tính giá trị của các cải tiến nhà tiếp theo bằng cách sử dụng dữ liệu do chủ nhà cung cấp.
Tóm lại, hầu hết các quy trình Máy học thực tế tròn và liên tục, vì dữ liệu bổ sung được thêm vào hoặc các tình huống thay đổi, bởi vì thế giới không bao giờ đứng yên, và luôn có chỗ để cải thiện.
Tóm lược
Sơ đồ dưới đây minh họa các chiến lược chính được các hệ thống Máy học sử dụng.
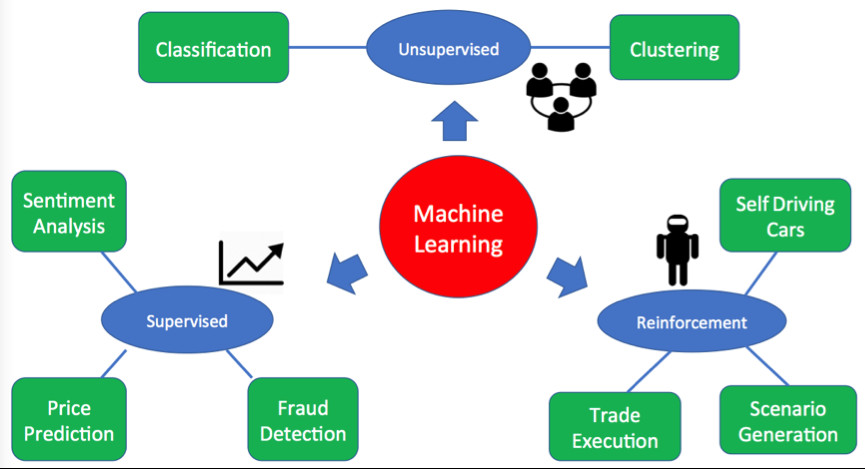
Tóm lại, thành phần quan trọng của bất kỳ hệ thống học máy nào là dữ liệu. Với sự lựa chọn của các thuật toán bổ sung, lập trình thông minh và số lượng lớn dữ liệu chính xác hơn - Big Data thắng mọi lúc.
Cảm ơn bạn đã đọc
Bạn cũng có thể quan tâm đến video dài 14 phút này trên Deep Mind của Google, giải thích cách các nhà khoa học ở Cambridge phát triển hệ thống Trí tuệ nhân tạo sử dụng học tập tăng cường để tự rèn luyện bản thân trong các trò chơi trên máy tính bao gồm Space Invaders. Rất gợi nhớ đến bộ phim "War Games" năm 1980.


